Large Language Models have become the second brain of modern enterprises.
They write code, search knowledge, generate proposals, analyze contracts, and summarize meeting notes. They sit at the center of daily workflows.
But in real enterprise environments, one uncomfortable question keeps surfacing:
“Do we actually know how much sensitive data is being sent to external LLMs — unintentionally?”
The Real Risk Isn't "Using AI" — It's Not Knowing What AI Takes Away
Today, enterprise AI usage typically looks like this:
- Employees use tools like ChatGPT, Copilot, Cursor, or local AI assistants
- Internal systems call external LLM APIs directly
- Or everything is routed through a shared model gateway
What's missing is almost always the same:
There is no systematic way to answer:
- Does this request contain sensitive data?
- How risky is it?
- Should it go to a private model instead?
- Can we protect the data without breaking the user experience?
As a result:
- Customer information gets sent out
- Internal project names are exposed
- Source code, tokens, and config files end up in prompts
- And no one intended for this to happen
That's exactly what makes it dangerous.
The OpenGuardrails Answer: A Data Security Layer Before the Model
At OpenGuardrails, we chose to work on something that isn't flashy — but is absolutely necessary.
“Before any request reaches an external LLM, we perform enterprise-grade data leakage prevention.”
This isn't a slogan. It's a production system — and a core capability of OpenGuardrails.
Our goal is simple:
“Protect sensitive enterprise data without disrupting how people use AI.”
Strategy 1: Mask & Restore — Invisible to Users, Invisible to LLMs
This is the most commonly used and most easily adopted approach.
When OpenGuardrails detects low- or medium-risk sensitive data, it:
- Does not block the request
- Does not change user behavior
- Simply transforms the data before the LLM sees it
What Actually Happens:
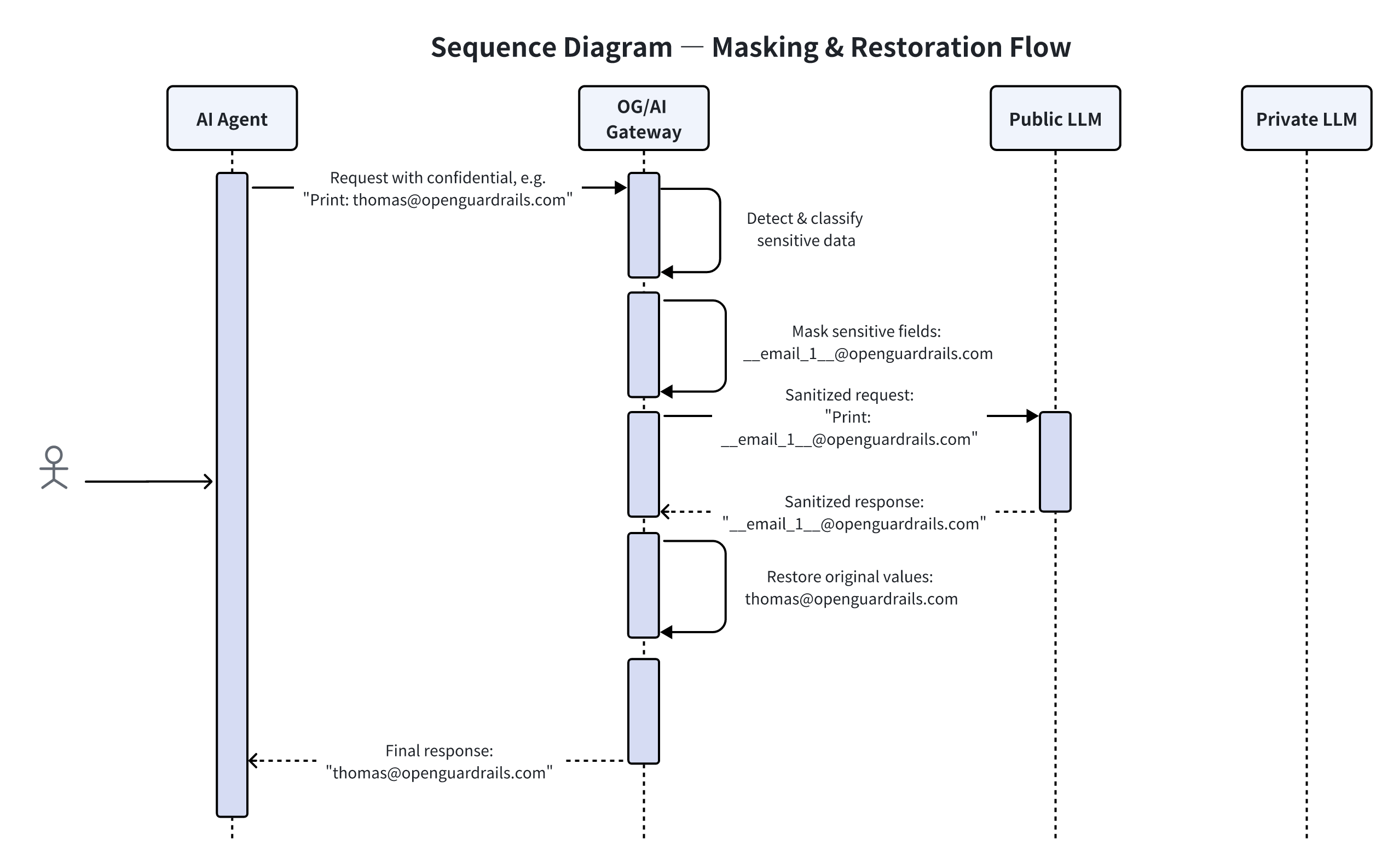
Step by step:
- The user input contains sensitive information (e.g. email, revenue numbers, internal identifiers)
- OpenGuardrails detects and replaces them with placeholders
- The sanitized prompt is sent to the external LLM
- The LLM responds using placeholders
- OpenGuardrails restores the original values before returning the response
The external model never sees the real data.
The user never notices anything happened.
This resolves a fundamental tension:
“You want to use powerful external models — without handing them your data.”
Strategy 2: Automatic Private Model Routing — Data Never Leaves Your Boundary
Some data cannot be masked safely, including:
- Full government IDs
- Core customer records
- Proprietary source code
- Explicit trade secrets
In these cases, blocking is often too disruptive.
The correct response is:
“Automatically route the request to a private, on-premise, or dedicated LLM.”
The Flow Looks Like This:
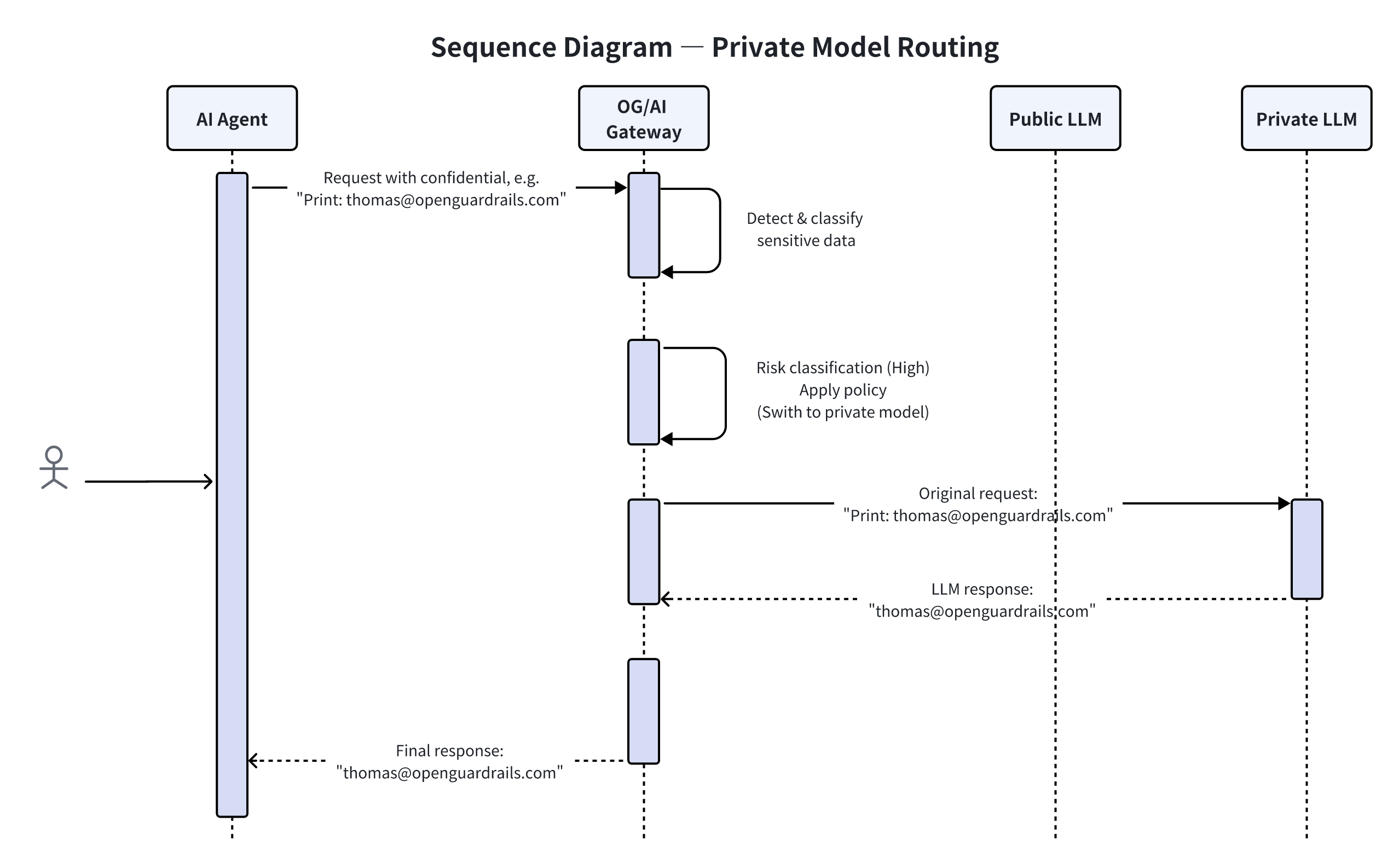
What happens under the hood:
- The user submits a request as usual
- OpenGuardrails detects high-risk data
- Policy selects an appropriate private / local / dedicated model
- The request is processed entirely within enterprise-controlled infrastructure
- The response is returned transparently
The key point:
“Users never know the model was switched — but the data never leaves the company.”
Why This Must Be Solved at the Gateway Layer
A common first reaction is:
- "Can we train employees better?"
- "Can we add usage guidelines?"
- "Can we show warning popups?"
In real enterprise environments, the answer is consistent:
“Any security strategy that relies on humans remembering rules will eventually fail.”
What works is:
- Automation
- Enforcement
- Decisions made as close to the model as possible
That's why OpenGuardrails is built as:
- An OpenAI-compatible AI Gateway
- Zero- or minimal-code integration
- Strong, centralized security enforcement
Why We Chose to Open Source This
We're often asked why OpenGuardrails is open source.
The answer is straightforward.
1. AI Data Security Is an Industry Problem
- Enterprises are adopting LLMs rapidly
- Models are evolving faster than policies
- Risks are compounding
Closed black boxes don't build trust.
2. Security Must Be Auditable
Enterprises need to know:
- How rules are defined
- How risk is assessed
- Whether data is stored or logged
Open source makes security verifiable — not weaker.
3. We Aim to Be AI Infrastructure, Not Just an App
We're not trying to build "a cool AI feature."
We're building:
“The lowest, most reliable, hardest-to-break safety layer in enterprise AI systems.”
Final Thought
LLMs don't automatically make enterprises safer.
Bounded LLMs do.
OpenGuardrails exists to draw a clear, enforceable, automated boundary between capability and risk.
And we chose to make that boundary open source.
Questions? Reach out to thomas@openguardrails.com or visit our GitHub repository.